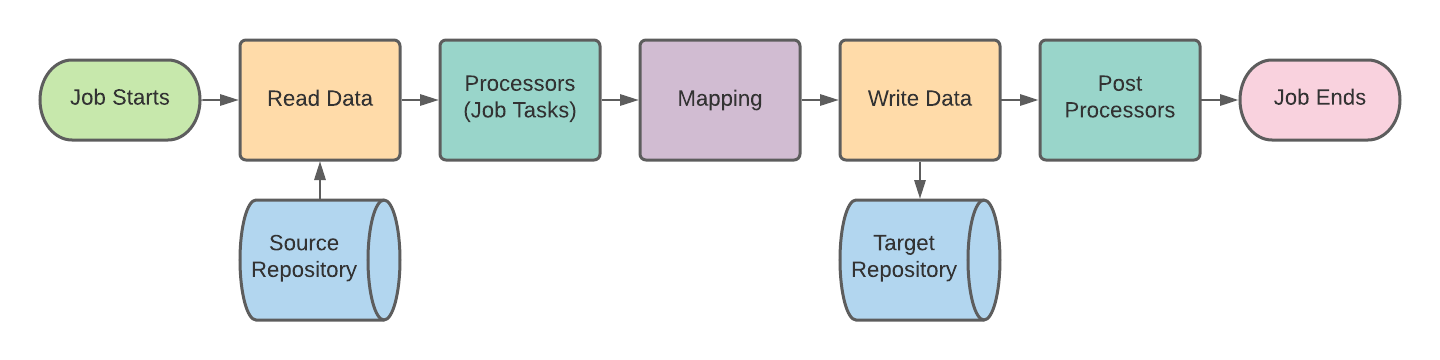
Simflofy Job Flow
In the diagram below you will see the order of operations for a basic Job in Simflofy. This job flow is the same whether you are using the job for migration, indexing, or data analytics.
It is important to note that the Processors (aka Job Tasks) will run against each Repository Document in the queue immediately after they are read from the repository, but before any mappings take place. This allows you to set fields on the Repository Document which can then be included in the mappings.
Post-processors will run after the document has been written to the target repository. This means you will have access to information about the newly created document. Most notably, you will know the newly created ID or UUID of the document. Only documents that have been successfully written to the target repository will be sent to the post processor. This is useful for performing work against the source repository without affecting un-migrated content (or content that failed to be read or processed). For example, if you want to lock the original file or delete the original file in the source repository you could leverage a post-processor for that task.
Job Process Flow